
The process of discovering molecules with the properties needed to create new medicines and materials is tedious, expensive, and consumes a huge amount of computational resources and months of human labor to narrow down the enormous space of the vast candidates.
Large-scale language models (LLMS) like CHATGPT can streamline this process, but it can allow LLM to understand the atoms and bonds that form molecules and present scientific stumbling blocks just like the words that form sentences.
Researchers at MIT and MIT-IBM Watson AI Lab have created a promising approach to enhancing LLM with other machine learning models known as graph-based models specifically designed to generate and predict molecular structures.
Those methods use the base LLM to interpret natural language queries specifying the desired molecular properties. Automatically switch between base LLM and graph-based AI modules to design molecules, explain the rationale, generate and synthesize step-by-step plans. Iteratively generates text, graphs, and synthetic step, combining words, graphs, and reactions into a common vocabulary for LLM to consume.
Compared to existing LLM-based approaches, this multimodal technique produced molecules that are more likely to better match user specifications and develop effective synthetic plans, and are more likely to improve the success ratio from 5% to 35%.
It also surpasses LLM, which is more than ten times its size, and surpasses design molecules and synthetic routes with text-based representation alone, suggesting that multimodality is the key to the success of new systems.
“We hope this will be an end-to-end solution that automates the entire molecular design and manufacturing process from start to finish. If LLM can give the answer in seconds, says Michael Sun, a graduate of MIT and a co-author of the technology’s paper.
Sun’s co-authors include Gang Liu, a graduate student at the University of Notre Dame, author Lead. Wojciech Matusik, professor of electrical engineering and computer science at MIT, leads the Computational Design and Manufacturing Group within the Computer Science and Artificial Intelligence Institute (CSAIL). Meng Jiang, an associate professor at the University of Notre Dame. Senior author Jie Chen, senior research scientist and manager at MIT-IBM Watson AI Lab. This research will be presented at the International Conference on Learning Expression.
Best in both worlds
Large-scale language models are not constructed to understand the nuances of chemistry. This is one reason why we struggle with inverse molecular design, a process that identifies molecular structures with specific functions or properties.
LLMS uses it to convert text into an expression called a token and to predict the next word in a sentence in order. However, molecules are “graph structures” and are composed of atoms and bonds.
On the other hand, strong graph-based AI models represent atoms and molecular bonds as interconnect nodes and edges in the graph. These models are popular for inverse molecular design, but require complex input, failing to understand natural language, and results that are difficult to interpret.
MIT researchers combined LLM and graph-based AI models into an integrated integrated framework to achieve the best in both worlds.
Short for a large-scale language model for molecular discovery, Llamole uses base LLM as a gatekeeper to understand user queries.
For example, users will probably look for molecules that can penetrate the blood-brain barrier and inhibit HIV, given their molecular weight of 209 and have specific binding properties.
LLM toggles the graph module to predict text according to the query.
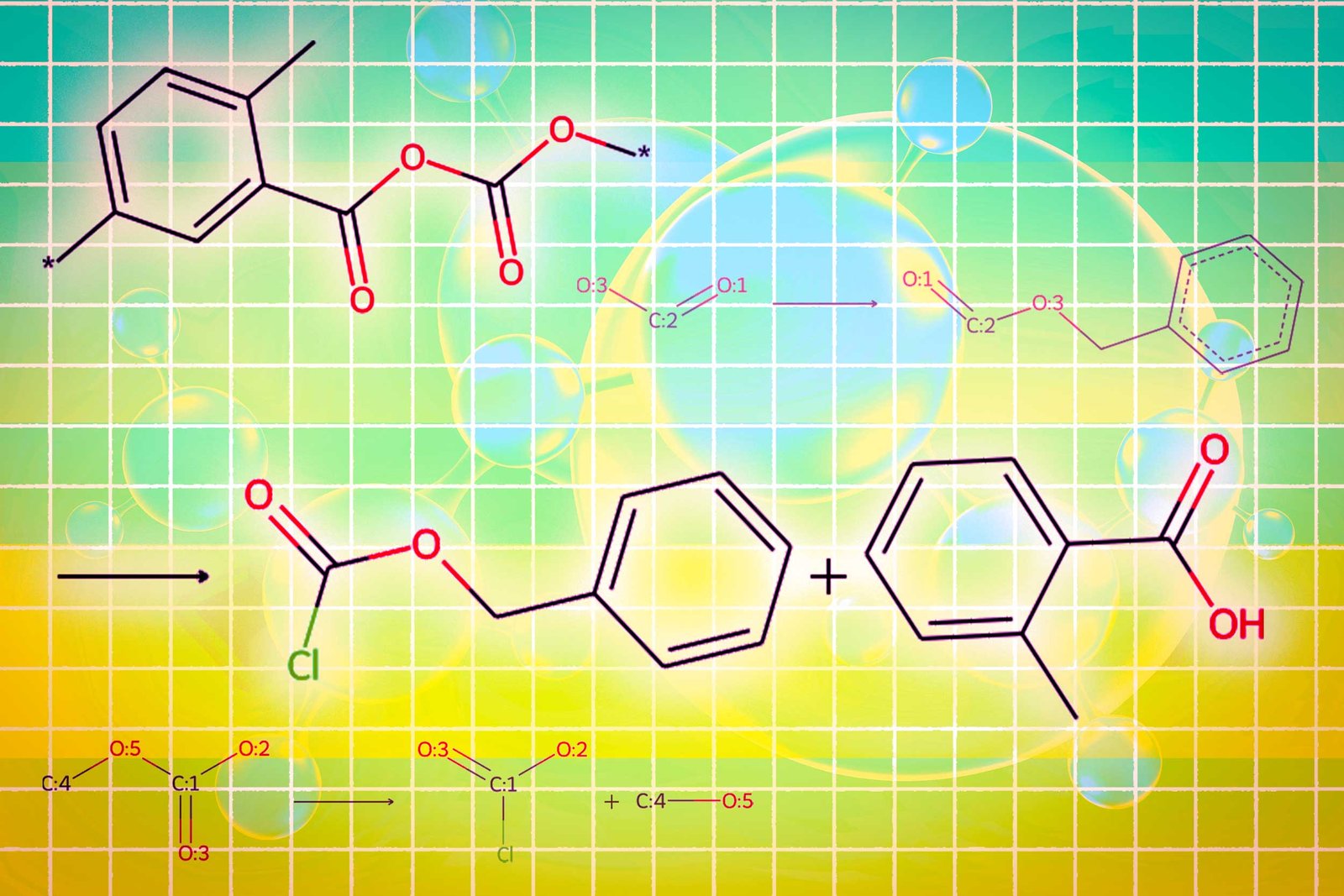
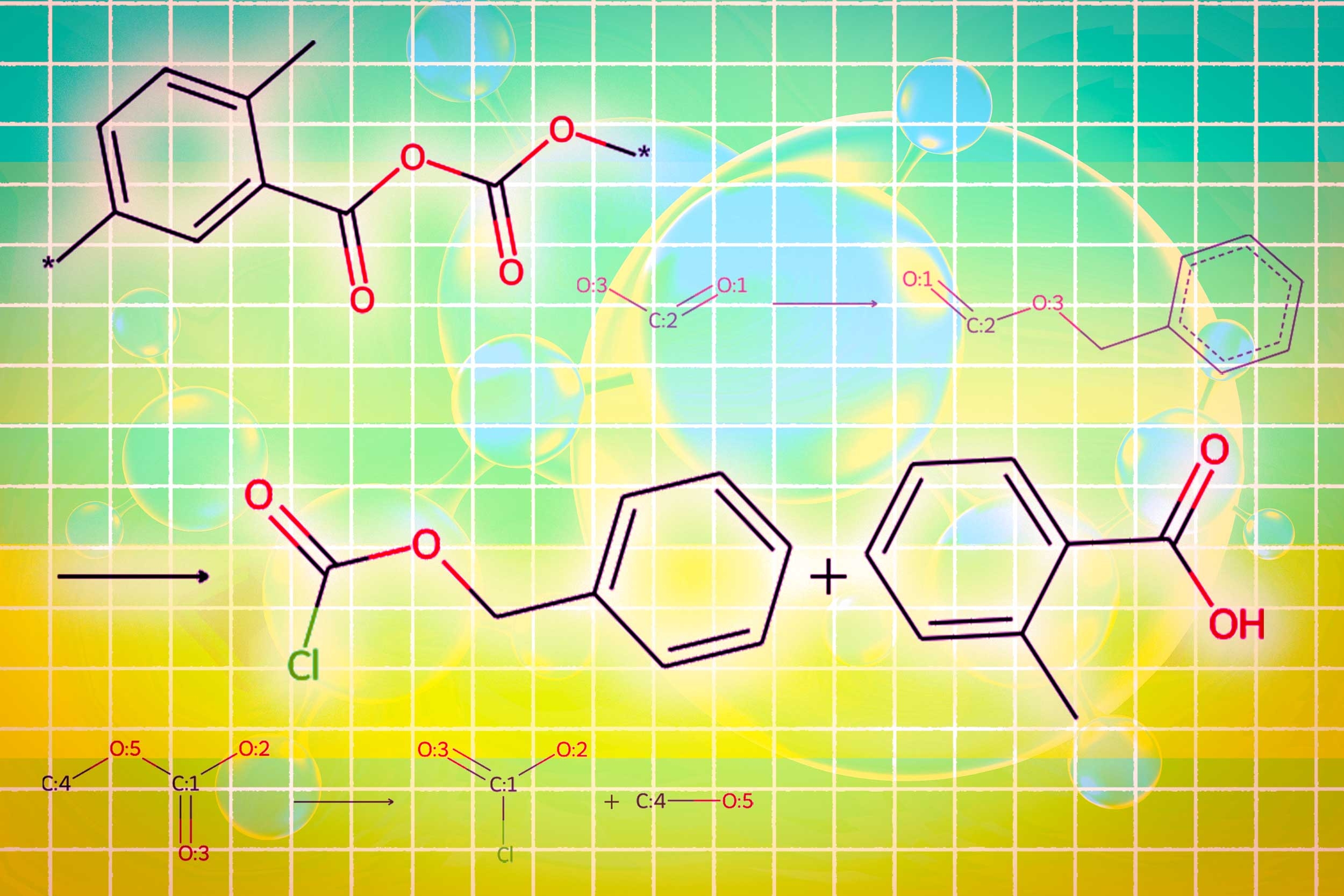
One module uses a graph diffusion model to generate molecular structures that are conditional on input requirements. The second module uses graph neural networks to return the generated molecular structure back to the token, consuming the LLMS. The final graph module is a graph reaction predictor that enters intermediate molecular structures and predicts reaction steps, searching for the exact set of steps for creating molecules from basic components.
The researchers have created a new type of trigger token that tells LLM when to activate each module. When LLM predicts the “design” trigger token, it switches to a module that sketches the molecular structure, and when predicting the “retro” trigger token, it switches to a retro-synthetic planning module that predicts the next reaction step.
“The beauty of this is that everything LLM generates before activating a particular module is fed to the module itself. The modules are learning to work in a way that matches the previous one,” says Sun.
Similarly, the output of each module is encoded and fed into the LLM generation process, so that you can understand what each module has done and continue to predict the token based on those data.
Better, simpler molecular structure
Finally, Llamole outputs a step-by-step synthetic plan that provides images of molecular structure, descriptions of the molecular text, and details of the methods leading up to individual chemical reactions.
In experiments involving the design of molecules consistent with user specifications, Llamole outperformed 10 standard LLMs, four fine-tuned LLMS, and state-of-the-art domain-specific methods. At the same time, the production of high-quality molecules increased the planning success rate of retrosynthes from 5% to 35%.
“LLMS has a hard time figuring out how to synthesize molecules because this requires a lot of multi-step planning. Our methods can produce better molecular structures that are easier to synthesize,” says Liu.
To train and evaluate Llamole, researchers built two datasets from scratch because existing datasets of molecular structures did not contain sufficient details. They augmented hundreds of thousands of patented molecules with AI-generated natural language descriptions and customized explanation templates.
One limitation of Llamole is that the dataset built to fine-tune LLM contains templates related to 10 molecular properties, so one of the limitations of Llamole is that they are trained to design molecules with only these 10 numerical properties in mind.
In future work, researchers want to generalize Llamole so that they can incorporate any molecular properties. Additionally, they plan to improve the graph module to increase the success rate of Llamole’s retrosynthesis.
In the long term, we would also like to use this approach to create multimodal LLMs that can work beyond molecules to process other types of graph-based data, such as power network interconnection sensors and financial market transactions.
“Llamole demonstrates the possibility of using large-scale linguistic models as an interface to complex data beyond textual explanations, and we expect it to be the foundation for interacting with other AI algorithms to solve graph problems,” says Chen.
This research is funded in part by the MIT-IBM Watson AI Lab, the National Science Foundation, and the Naval Research Bureau.

