
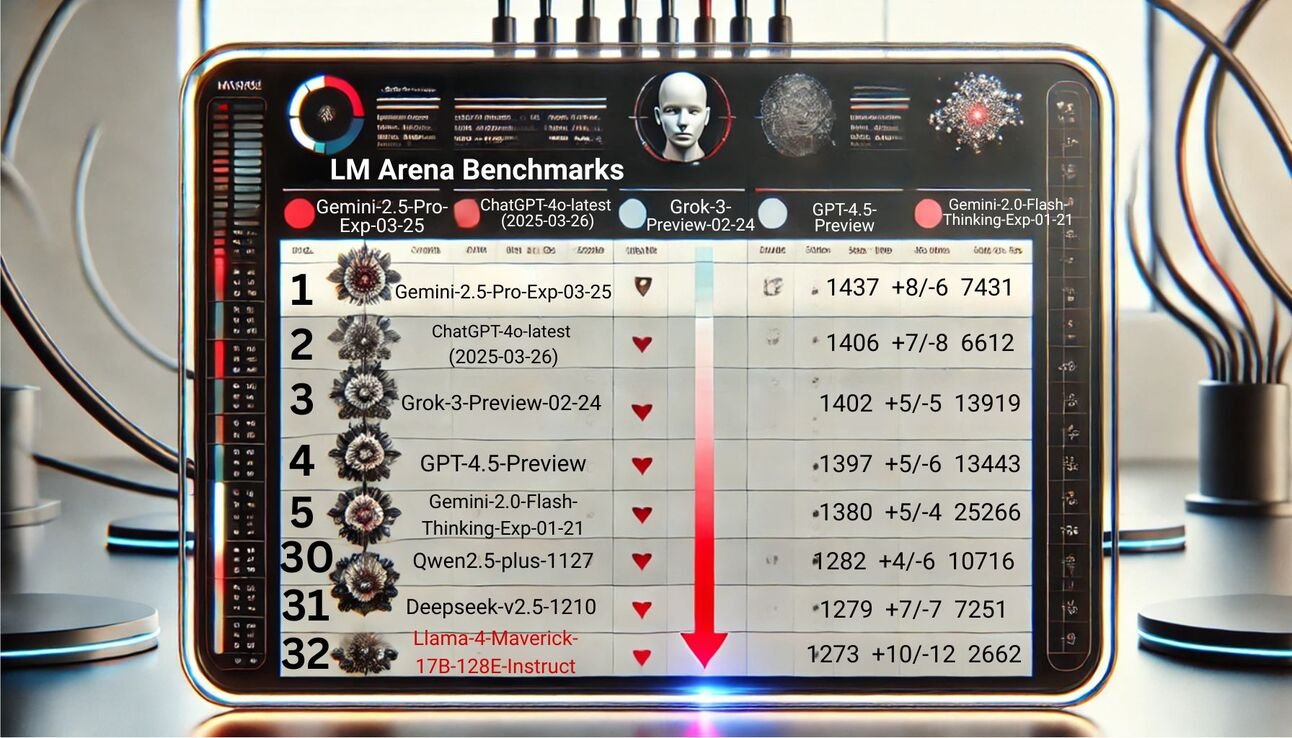

After eliciting criticism for submitting an unpublished experimental version of the Llama 4 Maverick model to LM Arena, Meta found that officially released versions were ranked.
The reevaluation is a version that Meta has been tailored specifically for chat performance following previous submissions for Llama-4-Maverick-03-26-Experimmal. This optimization initially gave the model the advantage of an LM arena that relies on human evaluators to evaluate the model’s response.
Following the pushback, the LM Arena moderator issued an apology, updated its submission policy and rescued the model using the unchanged, published version of the Llama-4-Maverick-17B-128E-Instruct.
result? The unchanged Maverick model was outperformed by several older rivals, including the GPT-4O, Claude 3.5 Sonnet and Gemini 1.5 Pro.
Meta said the experimental variant was “optimized for conversationality.” He said this is advantageous in the human comparison format at LM Arena. However, experts warn that optimizing a single benchmark can reduce the reliability of a wide variety of applications, making it difficult for developers to measure the true versatility of their models beyond what is misleading.
In a statement to TechCrunch, a Meta spokesperson said the company is often investigating multiple model variants.
“‘llama-4-maverick-03-26-Experimmal’ is the best version of chat that also worked well in the LM Arena. Release an open source version and see how developers can customize Lama 4 for their use cases.
Rankings reveal the difficulty of relying on narrow benchmarks to evaluate complex AI models, especially when experimental fine-tuning can distort the results. While the openness of the experimental meta may encourage innovation, this episode highlights the need for transparency and consistent assessment methods.
When Maverick proves value beyond the benchmark chart, it depends on how developers respond and the model’s performance when tested on Wild, where the leaderboard cannot provide shortcuts.
Editor’s Note: tHis article was created by Alicia Shapiro, CMO of AINEWS.COM, and provided support for writing, images and idea generation from AI assistant ChatGpt. However, the only final perspective and editorial choice is Alicia Shapiro. Thank you to ChatGpt for your research and editorial support in writing this article.

