
This article explains how vector databases and graph RAGs differ as memory architectures for AI agents, and when each approach is appropriate.
Topics covered include:
- How vector databases store and retrieve semantically similar unstructured information.
- How graph RAGs represent entities and relationships for accurate multihop search.
- How to choose between these approaches or combine them in a hybrid agent/memory architecture.
With that in mind, let’s get straight to the point.
Vector databases and graph RAGs for agent memory: when to use which?
Image by author
introduction
AI agent Long-term memory is required to be truly useful in complex multi-step workflows. Agents without memory are essentially stateless functions, resetting their context with every interaction. As we move toward autonomous systems managing persistent tasks, such as a coding assistant tracking a project architecture or a research agent compiling an ongoing literature review, the question of how context is stored, retrieved, and updated becomes important.
Currently, the industry standard for this task is vector databases, which use dense embeddings for semantic search. However, as the need for more complex inference increases, graph RAGs, which are architectures that combine knowledge graphs and large language models (LLMs), are gaining attention as a structured memory architecture.
At first glance, vector databases are ideal for broad similarity matching and searching unstructured data, but graph RAGs are better when the context window is limited or when multihop relationships, factual accuracy, and complex hierarchical structures are required. This difference highlights the focus of vector databases on flexible matching compared to the ability of graph RAGs to reason through explicit relationships and maintain accuracy under tighter constraints.
To clarify their respective roles, this article reviews the underlying theory, practical strengths, and limitations of both approaches to agent memory. Doing so provides a practical framework to guide you in choosing which system or combination of systems to deploy.
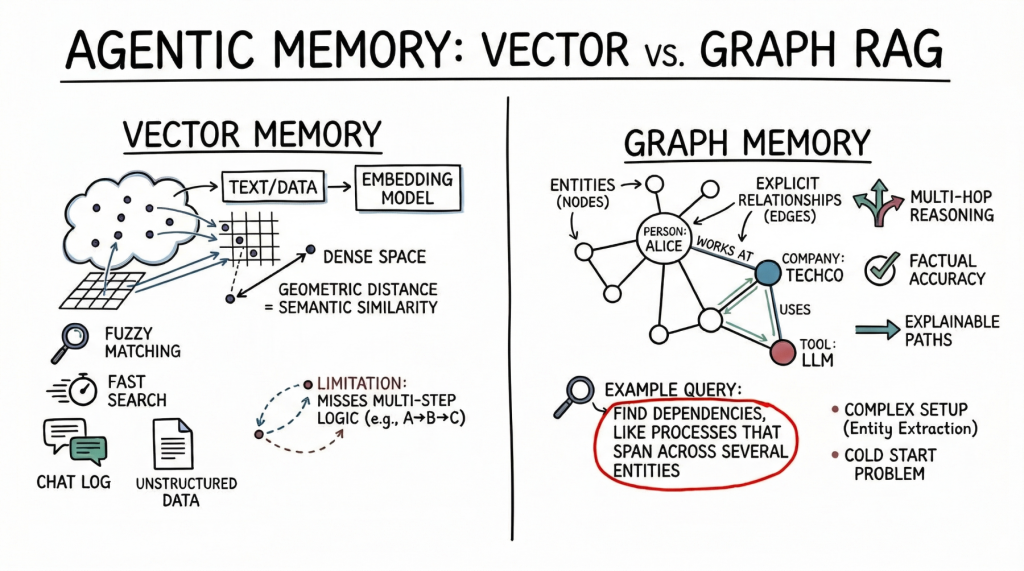
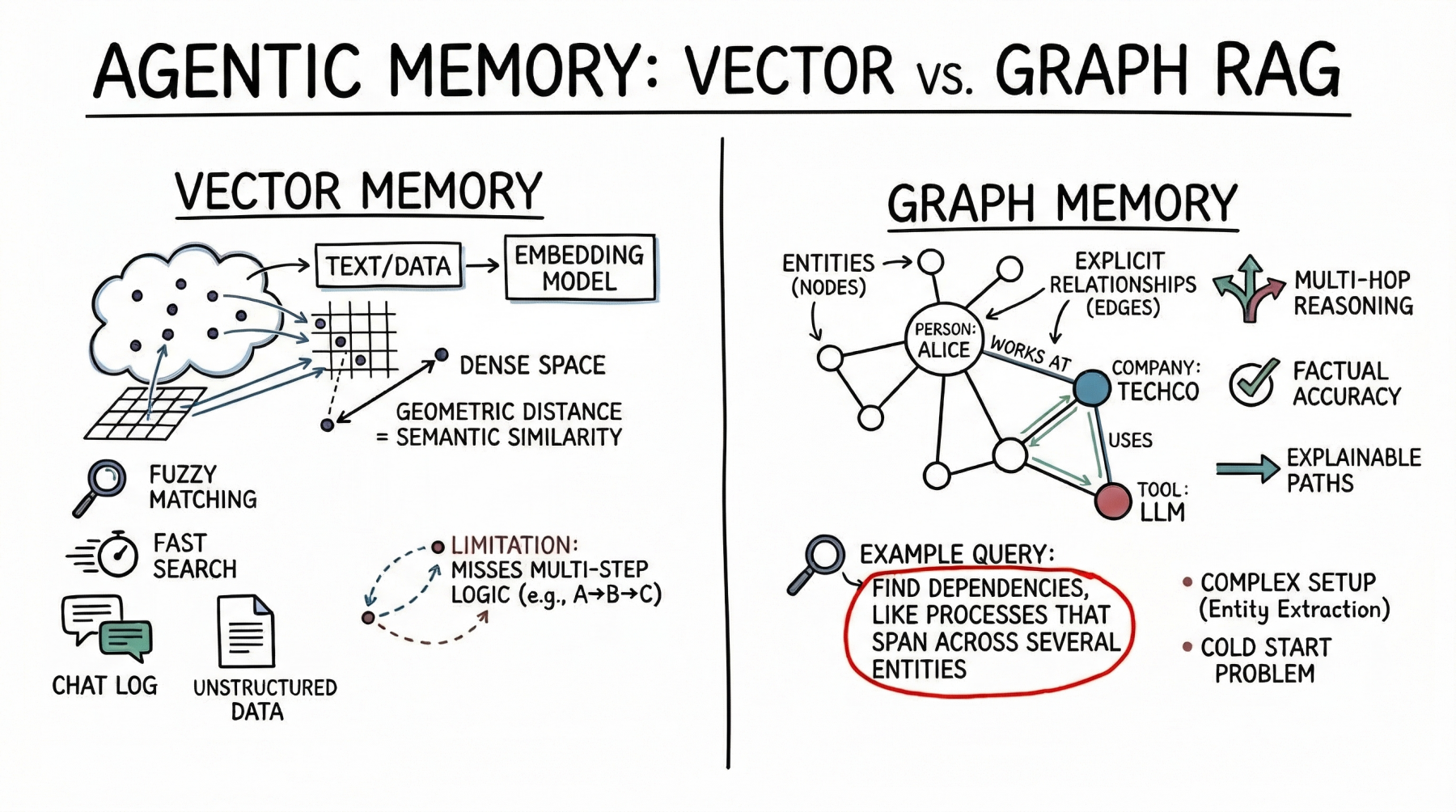
Vector Databases: Fundamentals of Semantic Agent Memory
vector database Represent memory as a dense mathematical vector, or embedding, located in a high-dimensional space. The embedded model maps text, images, or other data to an array of floats. Here, the geometric distance between two vectors corresponds to their semantic similarity.
AI agents primarily use this approach to store unstructured text. A common use case is storing conversation history so that the agent can remember what the user previously asked by searching its memory bank for semantically related past interactions. The agent also leverages the vector store to retrieve relevant documentation, API documentation, or code snippets based on the implicit meaning of the user’s prompt. This is a much more robust approach than relying on exact keyword matches.
Vector databases are a viable choice for agent memory. Fast searches even across billions of vectors. Developers will also find it easier to set up than structured databases. To integrate vector stores, split the text, generate embeddings, and index the results. These databases also handle fuzzy matches well, dealing with typos and paraphrases without requiring precise queries.
However, with semantic search, advanced agents have limited memory. Vector databases often cannot follow multi-step logic. For example, if an agent needs to find a link between entity A and entity C, but only has data showing that A connects to B and B connects to C, a simple similarity search may miss important information.
These databases also struggle when retrieving large amounts of text or processing noisy results. Dense, interconnected facts (from software dependencies to a company’s organizational chart) can be used to return related but unrelated information. This can cause the agent’s context window to become crowded with less useful data.
Graph RAG: Structured Context and Relational Memory
Graph RAG Combining knowledge graph and LLM addresses the limitations of semantic search. In this paradigm, memories are structured as discrete entities represented as nodes (e.g., people, companies, technologies), and explicit relationships between them are represented as edges (e.g., “works with” or “uses”).
Agents using graph RAGs create and update structured models of the world. As we collect new information, we extract entities and relationships and add them to the graph. When searching memory, follow an explicit path to get the exact context.
The main strength of graph RAG is its accuracy. There is a lower risk of error because the search follows explicit relationships rather than just semantic proximity. If a relationship does not exist in the graph, the agent cannot infer it from the graph alone.
Graph RAG excels at complex reasoning and is perfect for answering structured questions. To find the direct reports of the manager who approved the budget, follow the path through the organization and approval chain. Although this is a simple graph traversal, it is a difficult task for vector searches. Ease of explanation is also a big advantage. A search path is a clear and auditable sequence of nodes and edges, rather than an opaque similarity score. This is important for enterprise applications that require compliance and transparency.
On the downside, graph RAGs are significantly more complex to implement. Parsing raw text into nodes and edges requires a robust entity extraction pipeline, often requiring carefully tailored prompts, rules, or specialized models. Developers also need to design and maintain ontologies or schemas, which can be rigid and difficult to evolve when new domains are encountered. Cold start issues are also noticeable. Unlike vector databases, which are useful as soon as you embed text, knowledge graphs require significant up-front effort to enter data before answering complex queries.
Comparison frameworks: when to use which one?
When designing memory for AI agents, keep in mind that vector databases are better at handling unstructured high-dimensional data and suitable for similarity searches, whereas graph RAGs are advantageous for representing explicit relationships when entities and their relationships are important. Your choice should be determined by the unique structure of your data and expected query patterns.
Vector databases are ideal for purely unstructured data, such as chat logs, common documents, or vast knowledge bases built from raw text. This is useful when the purpose of the query is to explore a broad theme, such as “Find concepts similar to X” or “What did we discuss regarding topic Y?” From a project management perspective, low setup costs and high general accuracy make it the default choice for early stage prototypes and general-purpose assistants.
Conversely, graph RAGs are suitable for data with uniquely structured or semi-structured relationships, such as financial records, code-based dependencies, or complex legal documents. This is a good architecture when the query requires a precise, categorical answer, such as “How exactly is X related to Y?” or “What are the dependencies of this particular component?” The setup cost and ongoing maintenance overhead of a graph RAG system is justified because it can achieve high accuracy on specific connections where vector search would hallucinate, overgeneralize, or fail.
However, the future of advanced agent memory lies not in choosing between the two, but in hybrid architectures. An increasing number of major agent systems combine both methods. A common approach uses a vector database for the first search step and performs a semantic search to find the most relevant entry nodes in a large knowledge graph. Once these entry points are identified, the system moves to graph traversal to extract the precise relational context connected to those nodes. This hybrid pipeline combines the broad, fuzzy recall of vector embeddings with the strict, deterministic precision of graph traversal.
conclusion
Vector databases remain the most practical starting point for general-purpose agent memory due to their ease of deployment and powerful semantic matching capabilities. Capturing enough context is possible for many applications, from customer support bots to basic coding assistants.
But as we aim to achieve autonomous agents capable of enterprise-grade workflows, comprised of agents that need to reason about complex dependencies, ensure factual accuracy, and explain logic, graph RAGs are emerging as a key unlocker.
We recommend that developers take a layered approach. Start the agent’s memory with a vector database as the basis for basic conversations. As the agent’s reasoning requirements grow and we approach the practical limits of semantic search, we selectively deploy knowledge graphs to structure high-value entities and core operational relationships.

