
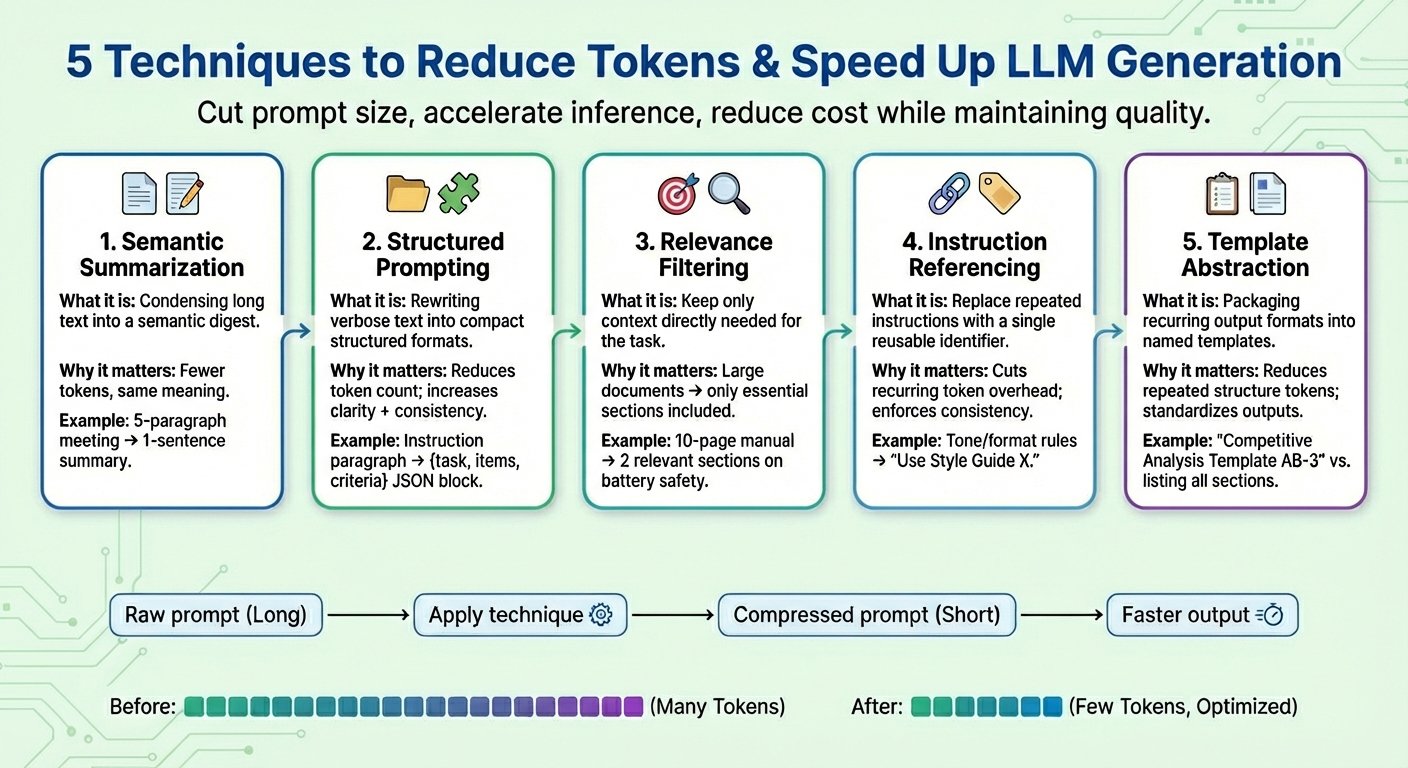
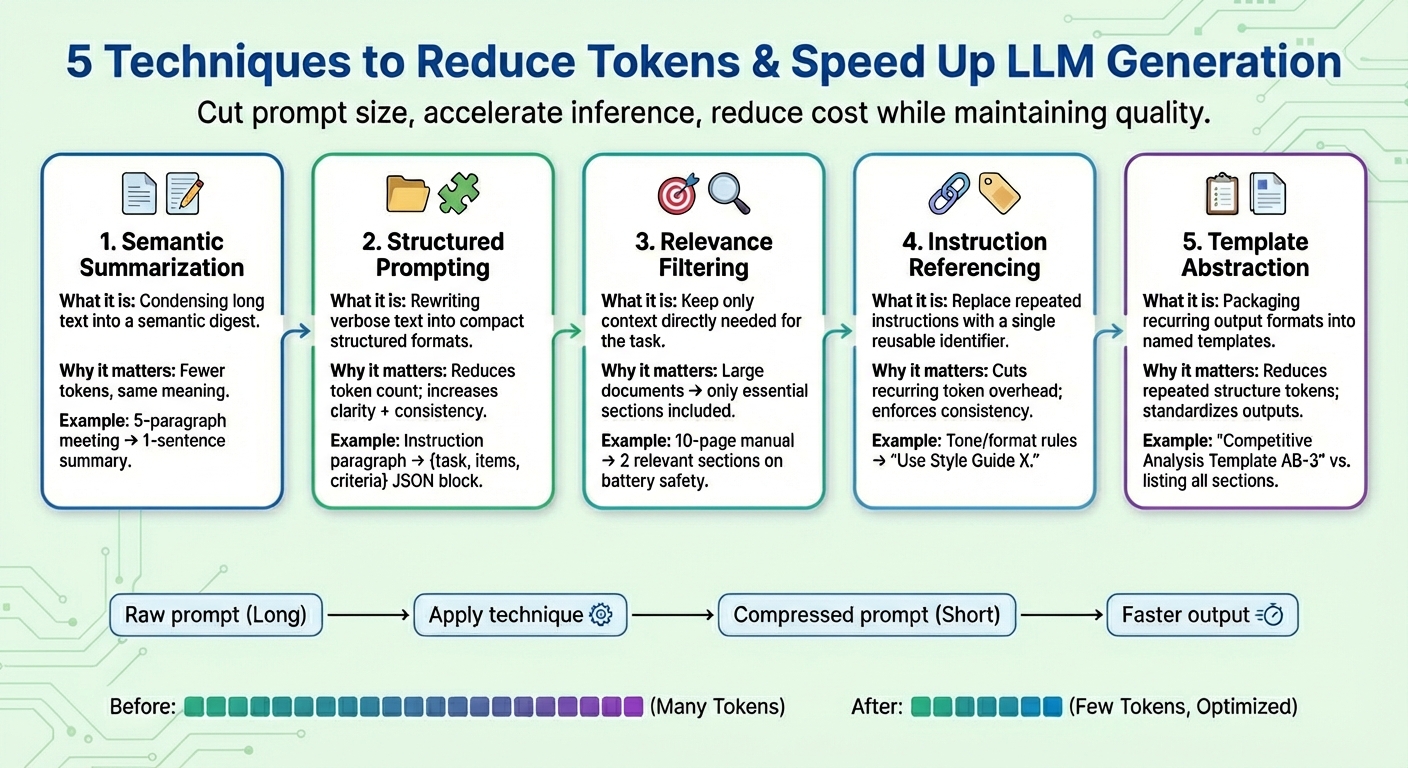
In this article, you will learn five practical prompt compression techniques that reduce tokens and speed up large-scale language model (LLM) generation without sacrificing task quality.
Topics covered include:
- What is Semantic Summarization and When to Use It?
- How to reduce token count with structured prompts, relevance filtering, and instruction references
- Where template abstraction is appropriate and how to apply it consistently
Let’s take a look at these techniques.
Optimize LLM generation and quickly compress for cost reduction
Image by editor
introduction
large language model (LLMs) are primarily trained to generate text responses to user queries and prompts, with complex inferences taking place under the hood that require not only language production by predicting each next token in the output sequence, but also a deep understanding of the language patterns surrounding the user input text.
Instant compression This technique is a research topic that has recently gained attention across LLM environments due to the need to alleviate slow and time-consuming inferences caused by large user prompts and context windows. These techniques are designed to reduce token usage, accelerate token generation, and reduce overall computational costs while preserving the quality of task results as much as possible.
This article introduces and discusses five commonly used prompt compression techniques to speed up LLM generation in difficult scenarios.
1. Summary of meaning
Semantic summarization is a technique that condenses long or repetitive content into a more concise version while preserving essential semantics. Rather than repeatedly feeding the entire conversation or text document to the model, a digest containing only the important parts is passed. As a result, the number of input tokens that the model needs to “read” is reduced, thereby speeding up the next token generation process and reducing costs without losing key information.
Assume a long prompt context consisting of meeting minutes such as “.At yesterday’s meeting, Ivan reviewed the quarterly numbers…”, summarizes up to five paragraphs. After the semantic summary, the abbreviated context looks like this:Summary: Iván reviewed the quarterly numbers, highlighted the decline in sales in the fourth quarter, and suggested cost-cutting measures.”
2. Structured (JSON) prompt
This technique focuses on representing long, smoothly flowing textual information in compact, semi-structured formats such as JSON (key-value pairs) or bulleted lists. Target formats used for structured prompts typically reduce the number of tokens. This allows the model to more reliably interpret the user’s instructions, resulting in a more consistent and less ambiguous model, while also reducing prompts along the way.
A structured prompting algorithm might transform the raw prompt with instructions like the following: Provide a detailed comparison of product X and product Y, focusing on price, product features, and customer ratings. Convert it to a structured format like this: {Task: “Compare”, Item: (“Product X”, “Product Y”), Criteria: (“Price”, “Features”, “Rating”)}
3. Relevance filtering
Relevance filtering applies the principle of “focus on what really matters.” This means measuring the relevance of parts of the text and incorporating only those parts of the context that are truly relevant to the task at hand into the final prompt. Rather than dumping the entire information, such as documents that are part of the context, only a small subset of the information most relevant to the target request is retained. This is another way to significantly reduce the size of the prompt and improve the behavior of the model in terms of focus and increased prediction accuracy (recall that LLM token generation is essentially a next word prediction task that is repeated many times).
For example, suppose the entire 10-page product manual for a mobile phone is added as an attachment (prompt context). Applying relevance filtering will only keep a few short relevant sections on “Battery Life” and “Charging Process”, as users will be prompted about safety implications when charging their device.
4. Reference to instructions
Many prompts repeat the same type of instructions over and over again, for example, “adopt this tone,” “reply in this format,” or “use concise sentences.” With instruction references, a reference is created for each common instruction (consisting of a set of tokens), each of which is registered only once and reused as a single token identifier. Whenever we refer to a registered “common request” in future prompts, that identifier will be used. This strategy not only shortens the prompt, but also helps maintain consistent task behavior over time.
It combines a series of instructions such as “Write in a friendly tone. Avoid jargon. Keep sentences concise. Provide examples.” This can be simplified to “Use Style Guide X.” It is then reused when the equivalent instruction is specified again.
5. Template abstraction
Some patterns and instructions often appear throughout the prompt, such as report structure, assessment format, and step-by-step instructions. Template abstraction applies similar principles to instruction references, but focuses on what shape and format the generated output should have, and encapsulates common patterns under template names. The template reference is then used and LLM takes care of filling in the remaining information. This not only makes the prompt clearer, but also greatly reduces the presence of repeated tokens.
After template abstraction, the prompt might change to something like “Create a competitive analysis using template AB-3.” Here, AB-3 is a list of content sections requested for analysis, each clearly defined. Something like:
Create a competitive analysis in four sections.
- Market overview (2-3 paragraphs summarizing industry trends)
- Competitor breakdown (table comparing at least 5 competitors)
- Advantages and disadvantages (bullet points)
- Strategic recommendations (3 actionable steps).
summary
This article introduces five commonly used methods to speed up LLM generation in difficult scenarios by compressing user prompts, and focuses on the context part. This is often the root cause of “prompt overload” that slows down LLM.

