
5 security patterns essential for robust agent AI
Image by editor
introduction
agent AIrevolves around autonomous software entities called agents, which are reshaping the AI landscape and influencing many of the most prominent developments and trends of recent years, including applications built on generative and language models.
Waves of major technologies like agent AI come with the need to secure these systems. This requires a shift from static data protection to dynamic, multi-step behavioral protection. This article lists five key security patterns for robust AI agents and highlights why they are important.
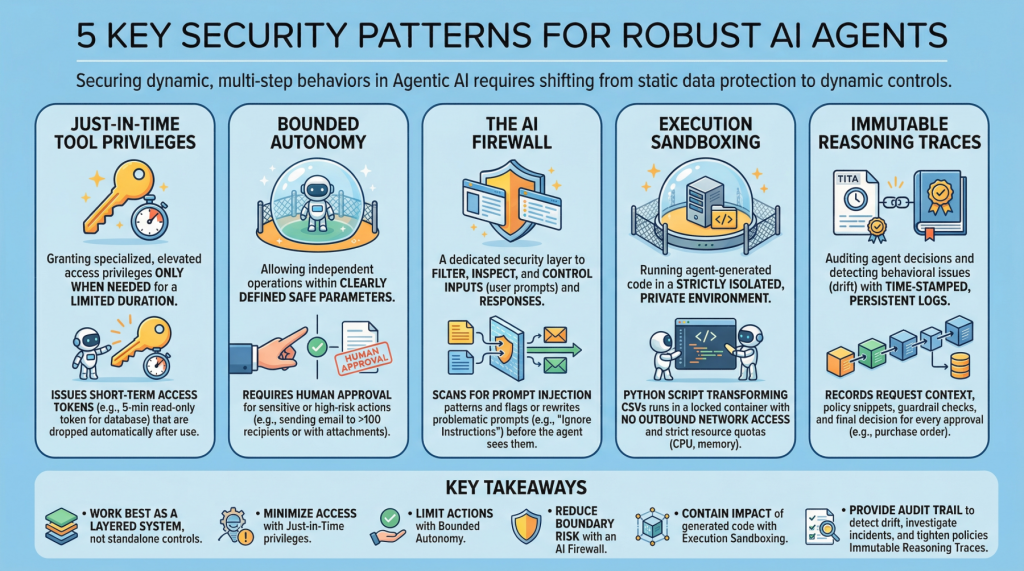
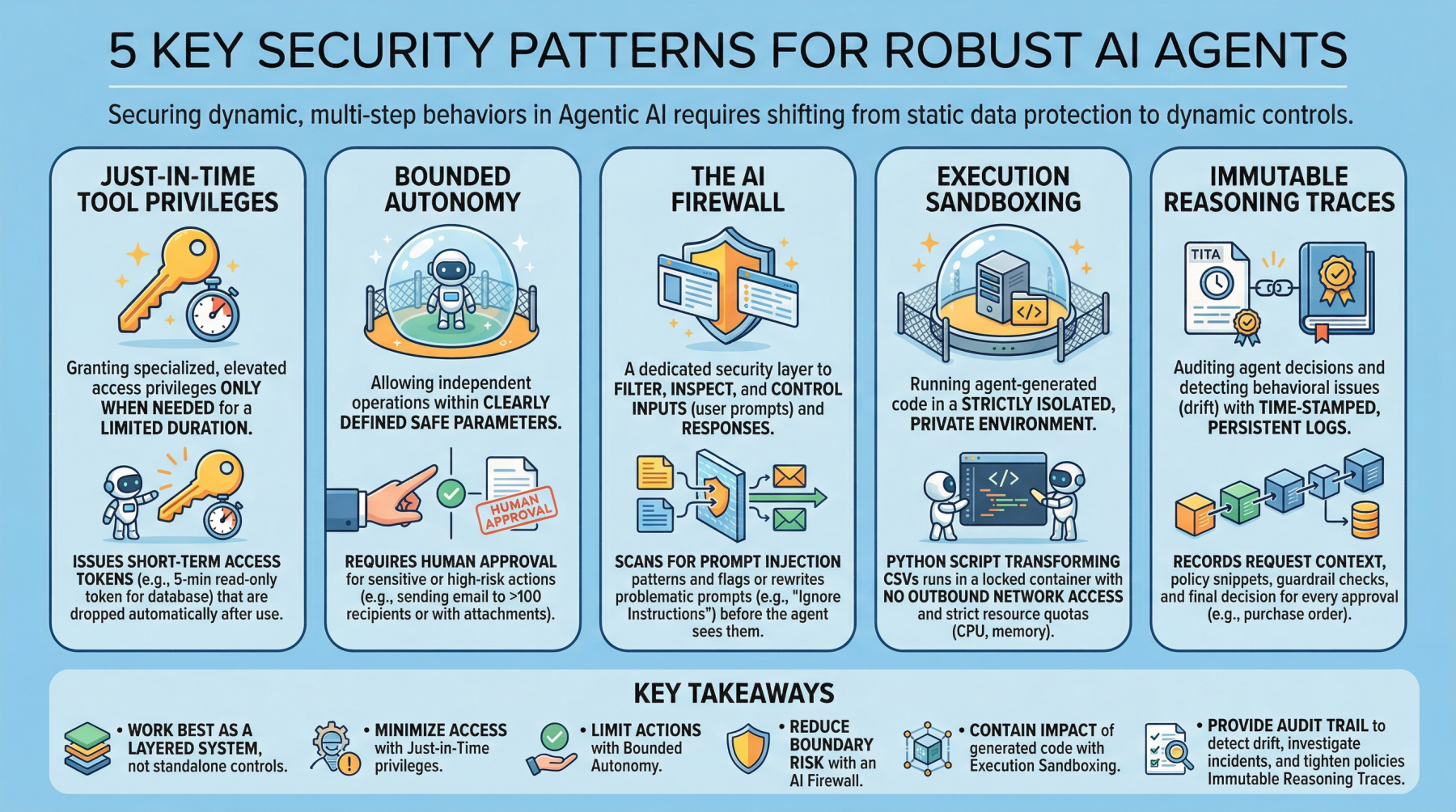
1. Just-in-time tool permissions
Often abbreviated as JIT, it is a security model that grants special or elevated permissions to users or applications only when needed and for a limited period of time. This is in contrast to traditional persistent permissions, which remain in place unless manually modified or revoked. In the field of agent AI, an example is issuing short-term access tokens to limit the “blast radius” if an agent is compromised.
example: Before the agent runs a billing adjustment job, it requests a narrow, five-minute read-only token against a single database table, and automatically deletes the token as soon as the query is complete.
2. Limited autonomy
This security principle allows AI agents to operate independently within restricted settings, i.e., within well-defined and secure parameters, balancing control and efficiency. This is especially important in high-risk scenarios where requiring human approval for sensitive actions can avoid catastrophic errors with full autonomy. In effect, this creates a control plane that reduces risk and supports compliance requirements.
example: Agents can draft and schedule outbound emails on their own, but messages to more than 100 recipients (or with attachments) are routed to a human for approval before sending.
3. AI firewall
This refers to a dedicated security layer that filters, inspects, and controls inputs (user prompts) and subsequent responses to protect AI systems. This helps protect against threats such as instant injections, data leaks, and harmful or policy-violating content.
example: Incoming prompts are scanned for prompt insertion patterns (for example, requests that ignore advance instructions or reveal secrets), and flagged prompts are blocked or rewritten to a more secure format before being reviewed by agents.
4. Execution sandboxing
Run agent-generated code within a strictly isolated private environment or network perimeter. This is known as an execution sandbox. Helps prevent unauthorized access, resource exhaustion, and potential data breaches by limiting the effects of unreliable or unpredictable execution.
example: The agent that writes Python scripts to convert CSV files runs them in a locked-down container with no outbound network access, strict CPU/memory quotas, and read-only mounts for input data.
5. Immutable inference traces
This practice supports auditing the decisions of autonomous agents and detecting behavioral issues such as drift. This requires building time-stamped, tamper-explicit, persistent logs that capture agent input, key intermediate artifacts used in decision-making, and policy checks. This is an important step towards transparency and accountability for autonomous systems, especially in high-stakes application areas such as procurement and finance.
example: For every purchase order an agent approves, record the request context, snippets of policies captured, guardrail checks applied, and final decisions in a write log that can be independently verified during an audit.
Important points
These patterns work best as a layered system rather than a standalone control. Privileges for just-in-time tools minimize what agents can access at any given time, while limited autonomy limits the actions agents can take without being observed. AI firewalls reduce risk at interaction boundaries by filtering and shaping inputs and outputs, and execution sandboxes include the effects of code generated or executed by agents. Finally, immutable inference traces provide an audit trail that allows you to detect drift, investigate incidents, and continuously enforce policies over time.
| security pattern | explanation |
|---|---|
| Just-in-time tool permissions |
Allow short-term, narrow-area access only when necessary to reduce the explosive radius of a breach. |
| limited autonomy |
Limit the actions agents can take independently and route sensitive steps through authorizations and guardrails. |
| AI firewall |
Filter and inspect prompts and responses to block or neutralize threats such as prompt injections, data leaks, and harmful content. |
| Execution sandboxing |
Agent-generated code runs in an isolated environment with strict resource and access controls to limit harm. |
| immutable inference trace |
Create time-stamped, tamper-proof logs of inputs, intermediate artifacts, and policy checks for auditability and drift detection. |
These limitations reduce the likelihood that a single failure will escalate into an overall breach, without compromising the operational benefits that make agentic AI so appealing.

