
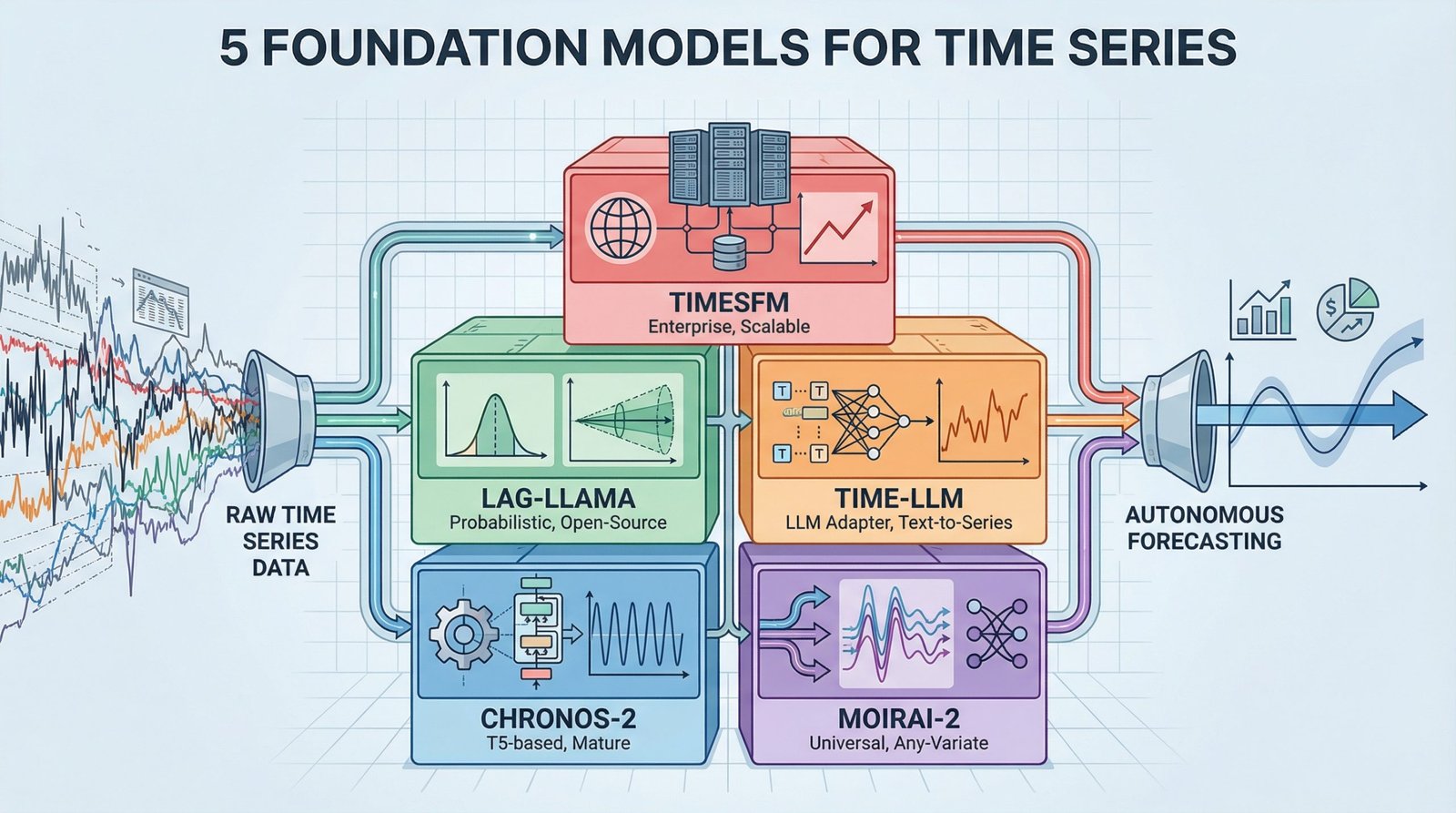
2026 Time Series Toolkit: Five Fundamental Models for Autonomous Forecasting
Image by author
introduction
Most predictive work involves building custom models for each dataset. In other words, apply ARIMA here, adjust LSTM, prophethyperparameters. The Foundation model reverses this. They are pre-trained on large amounts of time series data and can predict new patterns without additional training. This is similar to how GPT writes about topics it hasn’t explicitly seen. This list features five important foundational models you need to know to build a production forecasting system for 2026.
Moving from task-specific models to orchestration of underlying models changes the way teams approach forecasting. Instead of spending weeks tuning parameters or considering domain expertise for each new dataset, pre-trained models already understand universal temporal patterns. Teams achieve faster deployment, better generalization across domains, and lower computational costs without large-scale machine learning infrastructure.
1. Amazon Chronos-2 (Production Ready Foundation)
Amazon Kronos-2 This is the most mature option for teams moving to underlying model predictions. This family of pre-trained transformer models is based on the T5 architecture and tokenizes time series values through scaling and quantization, treating prediction as a language modeling task. The October 2025 release expands functionality to support univariate, multivariate, and covariate-based predictions.
This model provides state-of-the-art zero-shot predictions that consistently outperform tuned statistical models and processes over 300 predictions per second on a single GPU. With millions of downloads, hug face Native integration with AWS tools sage maker and autogluonChronos-2 has the strongest documentation and community support of any foundation model. The architecture has five sizes ranging from 9 million to 710 million parameters, allowing teams to balance performance against computational constraints. You can see the implementation on GitHub, check the technical approach in the research paper, and get a pre-trained model from Hugging Face.
2. Salesforce MOIRAI-2 (universal forecaster)
Salesforce MOIRAI-2 tackles the practical challenge of processing messy real-world time series data through a universal predictive architecture. This decoder-specific transformer underlying model accommodates any data frequency, any number of variables, and any prediction length within a single framework. The model’s “arbitrary variate attention” mechanism distinguishes it from models designed for specific data structures, as it dynamically adjusts to multivariate time series without requiring fixed input dimensions.
MOIRAI-2 ranks high on the GIFT-Eval leaderboard among non-data leakage models and has good performance on both distributed and zero-shot tasks. Training on the LOTSA dataset (27 billion observations across nine domains) allows the model to generalize robustly to new predictive scenarios. Teams can benefit from fully open source development with active maintenance, which is valuable for complex real-world applications involving multiple variables and irregular frequencies. The project’s GitHub repository contains implementation details, and technical documentation and a Salesforce blog post describe the universal prediction approach. Pre-trained models can be found at Hugging Face.
3. Lag-Llama (Open Source Backbone)
Ragrama We bring probabilistic prediction capabilities to the underlying model through a decoder-specific transformer inspired by Meta’s LLaMA architecture. Unlike models that only produce point predictions, Lag-Llama produces an uncertainty interval for each prediction step, a complete probability distribution containing the quantified uncertainty required for the decision-making process. This model uses lag features as covariates and exhibits strong few-shot learning when fine-tuned on small datasets.
Lag-Llama’s fully open source nature with a permissive license makes it accessible to teams of all sizes, and the ability to run on CPU or GPU removes infrastructure barriers. Academic backing with publications at major machine learning conferences provides additional validation. Lag-Llama provides a reliable underlying model backbone for teams that prioritize transparency, reproducibility, and probabilistic output over raw performance metrics. The GitHub repository contains the implementation code, and the research paper details the probabilistic prediction technique.
4. Time-LLM (LLM Adapter)
Time-LLM takes a different approach by converting an existing large-scale language model into a prediction system without changing the weights of the original model. This reprogramming framework transforms time-series patches into text prototypes, allowing frozen LLMs such as GPT-2, LLaMA, and BERT to understand temporal patterns. “Prompt as prefix” technology injects domain knowledge through natural language, allowing teams to predict tasks using their existing language model infrastructure.
This adapter approach is suitable for organizations that are already running LLM in production because it eliminates the need to deploy and maintain a separate predictive model. The framework supports multiple backbone models, so you can easily switch between different LLMs when new versions become available. Time-LLM represents an “agent AI” approach to prediction, where general language understanding capabilities are transferred to temporal pattern recognition. Access the implementation through the GitHub repository or review the methodology in the research paper.
5. Google TimesFM (Big Tech Standard)
Google Times FM provides enterprise-grade foundational model predictions backed by one of the largest technology research organizations. This patch-based decoder-only model is pre-trained on 100 billion real-world timepoints from Google’s internal datasets and delivers strong zero-shot performance across multiple domains with minimal configuration. The model design prioritizes large-scale production deployments and reflects its origins in Google’s internal predictive workloads.
TimesFM has been rigorously tested through extensive use in Google’s production environments, giving teams confidence in deploying the underlying model in business scenarios. This model balances performance and efficiency, avoiding the computational overhead of large alternative models while maintaining competitive accuracy. Ongoing support from Google Research ensures continued development and maintenance, making TimesFM a reliable choice for teams seeking enterprise-grade foundational model functionality. Access the model through the GitHub repository, review the architecture in the technical documentation, or read implementation details in the Google Research blog post.
conclusion
The underlying model transforms time series forecasting from a model training problem to a model selection problem. Chronos-2 provides operational maturity, MOIRAI-2 processes complex multivariate data, Lag-Llama provides probabilistic output, Time-LLM leverages existing LLM infrastructure, and TimesFM provides enterprise reliability. Evaluate models based on your specific needs for uncertainty quantification, multivariate support, infrastructure constraints, and deployment size. Before investing in fine-tuning or custom development, start with a zero-shot evaluation of representative datasets to identify a foundational model that fits your prediction needs.
About Vinod Chugani
Vinod Chugani is an AI and data science educator and author of two comprehensive e-books on Machine Learning Mastery. Beginner’s guide to data science and Next level data science. His articles focus on data science fundamentals, machine learning applications, reinforcement learning, AI agent frameworks, and emerging AI technologies, making complex concepts practical for practitioners at all levels. Through his work in education and mentoring, Vinod specializes in breaking down advanced ML algorithms, AI implementation strategies, and emerging frameworks into clear, practical learning paths. He brings analytical rigor to his teaching approach from a background in quantitative finance and experience scaling global technology ventures. Having grown up across multiple countries, Vinod creates accessible content that clarifies advanced AI concepts for learners around the world. Connect with Vinod on LinkedIn.

