


10 Python one-liners to calculate model feature importance
Image by editor
Understand machine learning models It is a key element in building reliable AI systems. The understandability of such models is based on two fundamental properties: explainability and interpretability. The former refers to how well it can explain the “inside” of the model (i.e., how it works and looks internally), and the latter concerns how easily humans can understand the captured relationships between input features and predicted outputs. As you can see, the differences between the two are subtle, but there is a strong bridge that connects them both. Importance of features.
This article introduces 10 simple but effective Python one-liners to calculate the importance of features in your model from different perspectives. This helps you understand not only how your machine learning model works, but also why it made the predictions it made.
1. The importance of built-in features in decision tree-based models
Tree-based models such as random forests XG boost Ensembles allow you to easily obtain a list of feature importance weights using attributes such as:
|
importance = model.Feature_Importance_ |
note that model Must contain a pre-trained model. The result is an array containing the feature importance, but if you want a more readable version, this code extends the previous one line by incorporating all the feature names from a dataset such as iris in one line.
|
print(“The importance of features:”, list(zip(iris.Function name, model.Feature_Importance_))) |
2. Coefficients of linear model
Simpler linear models, such as linear regression and logistic regression, also reveal feature weights via learned coefficients. This is a direct and clean way to get the first value (remove the position index and get all the weights).
|
importance = abs(model.coefficient_(0)) |
3. Sorting features by importance
Similar to the enhanced version of 1 above, you can use this handy one-liner to rank features in descending order based on their importance values. At a glance, you can see which features have the strongest or most impact on model predictions.
|
sorted features = sorted(zip(Features, importance), key=lambda ×: ×(1), go backwards=truth) |
4. Importance of model-independent substitution
Permutation importance is an additional approach to measuring feature importance. That is, by shuffling its values and analyzing how the metrics used to measure the model’s performance (such as accuracy and error) are reduced. So this model independent one-liner is: scikit-learn Used to measure performance degradation as a result of randomly shuffling feature values.
|
from Scran.inspection import Importance of permutations result = Importance of permutations(model, ×, y).importance_average |
5. Average precision loss in cross-validation permutations
This is an efficient one-liner for testing permutations in the context of a cross-validation process, analyzing how shuffling each feature affects the overall model performance. K fold.
|
import lump as NP from Scran.model selection import crossval score importance = ((crossval score(model, ×.assign(**{f: NP.random.permutation(×(f))}), y).average()) for f in ×.column) |
6. Visualizing permutation importance with Eli5
Eli 5 — short for “Explain like I’m 5 (years old)” — is a library that enables very clear explainability in the context of Python machine learning. It’s particularly useful for notebooks, as it displays feature importance in a visually friendly and interactive HTML view, and is equally suited to trained linear and tree models.
|
import Eli 5 Eli 5.show_weights(model, Function name=Features) |
7. Importance of global SHAP function
sharp is a popular and powerful library for explaining the importance of model features in more depth. This can be used to calculate the average absolute SHAP value (feature importance metric in SHAP) for each feature under a model-independent, theory-based measurement approach.
|
import lump as NP import shape shape value = shape.tree explainer(model).shape value(×) importance = NP.abs(shape value).average(0) |
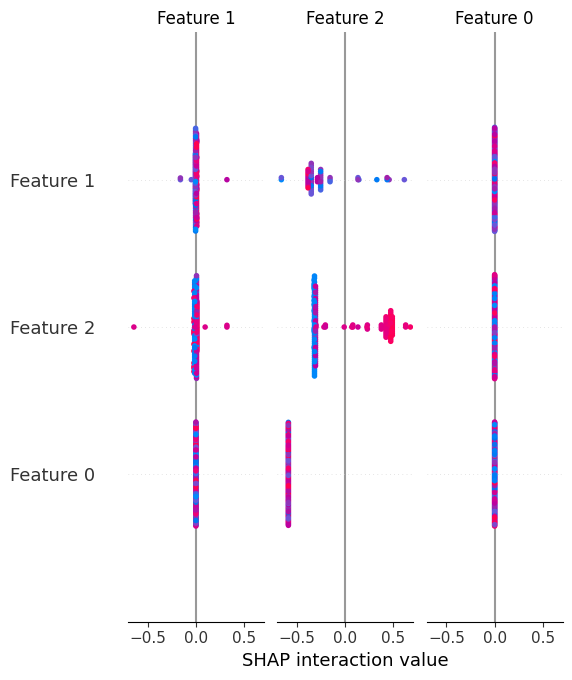
8. Summary plot of SHAP values
Unlike the global SHAP feature importance, summary plots provide not only the overall importance of features in the model, but also their direction, helping you visually understand how features drive predictions upward or downward.
|
shape.Summary_Plot(shape value, ×) |
Let’s look at a visual example of the results obtained.
9. Explaining a single prediction with SHAP
One particularly attractive aspect of SHAP is that it helps explain not only the overall model behavior and the importance of features, but also how features specifically influence a single prediction. In other words, you can reveal or decompose individual predictions to explain how and why the model produced that particular output.
|
shape.force plot(shape.tree explainer(model).Expected value, shape value(0), ×.iloc(0)) |
10. Importance of model-independent features in LIME
lime is an alternative library to SHAP that generates local surrogate descriptions. Rather than using one or the other, these two libraries complement each other and help better approximate the importance of features for individual predictions. This example does this for a previously trained logistic regression model.
|
from lime.lime tabular format import Lime tabular explainer Experience points = Lime tabular explainer(×.values, Function name=Features).description_instance(×.iloc(0), model.prediction proba) |
summary
In this article, we introduced 10 effective Python one-liners to help you better understand, explain, and interpret machine learning models by focusing on the importance of features. With these tools, understanding how your model works from the inside is no longer a mysterious black box.

